Chapter 05
Generate, execute, and recheck
Finish the workflow by selecting the final knowledge set, loading the LLM, previewing the prompt, generating structured commands, executing the edit, saving the model, and running IDS checking again.
Prepare the final knowledge set
A useful generation request usually combines project documents with structured model and IDS knowledge. Before loading the model for generation, check that the relevant files are visible and selected.
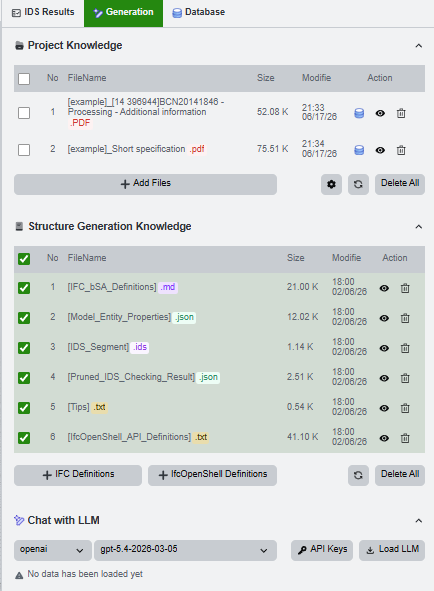
Load the LLM
In the Chat with LLM panel, choose a provider and model, then load the model. If the server does not already have a key, use the temporary API key dialog first.
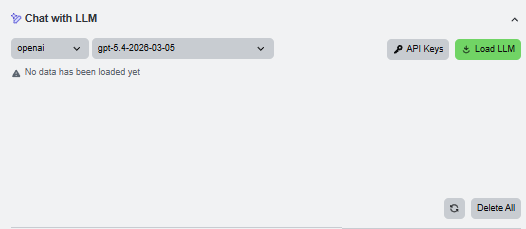
Use temporary API keys
The API key dialog accepts provider keys for the current browser session. The keys are not written to the server file system; they are used only for requests made while the page is open.
After applying a key and loading the model, the page confirms the model initialization through a toast.

Check the prepared knowledge before generation
The generation workflow begins after the project documents and structural knowledge have been selected. The panel should show the relevant chips and the LLM controls together.
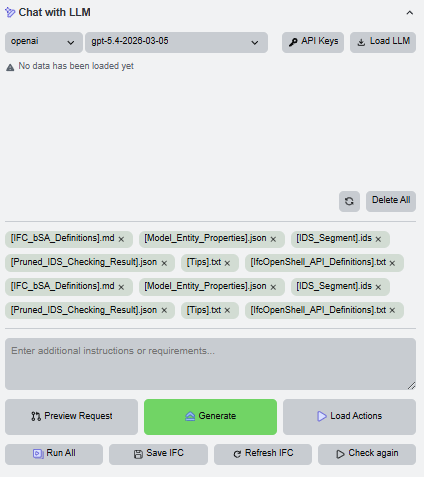
Before sending a request, open the preview to confirm the prompt structure, role, inputs, and the knowledge that will be used.
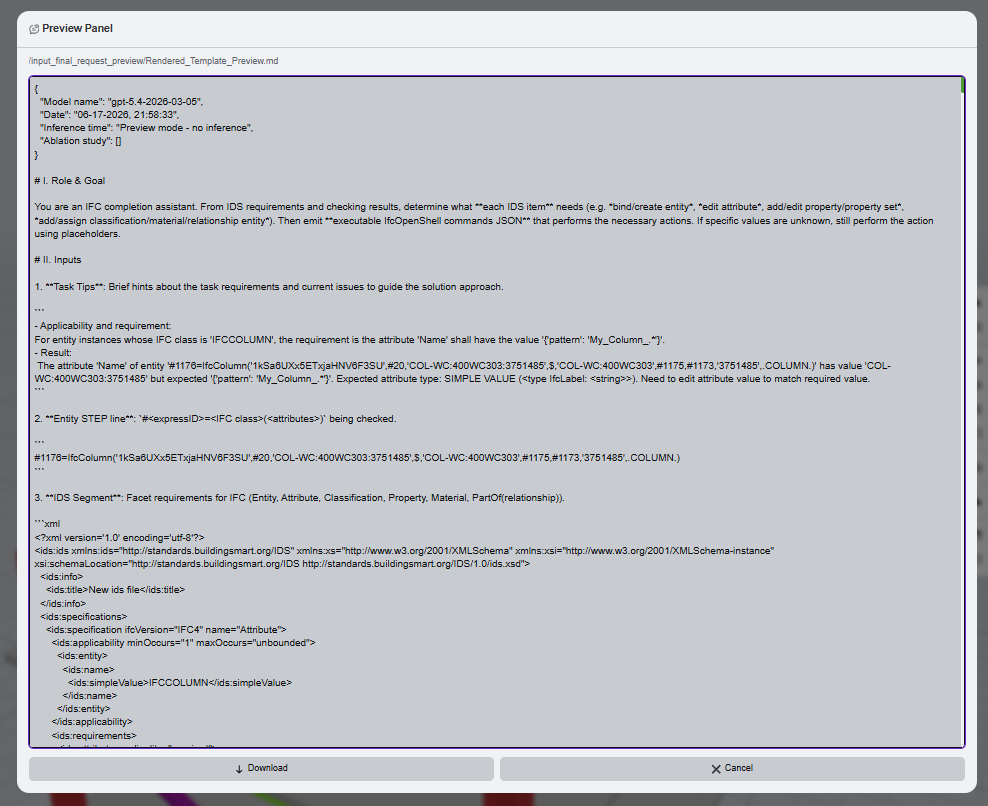
Read the generated result
Once the request is sent, the application shows a success toast and stores the generated script and action list in the panel below.

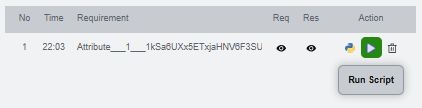

Execute and verify
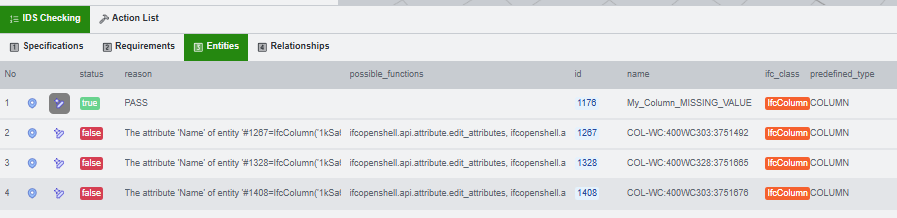
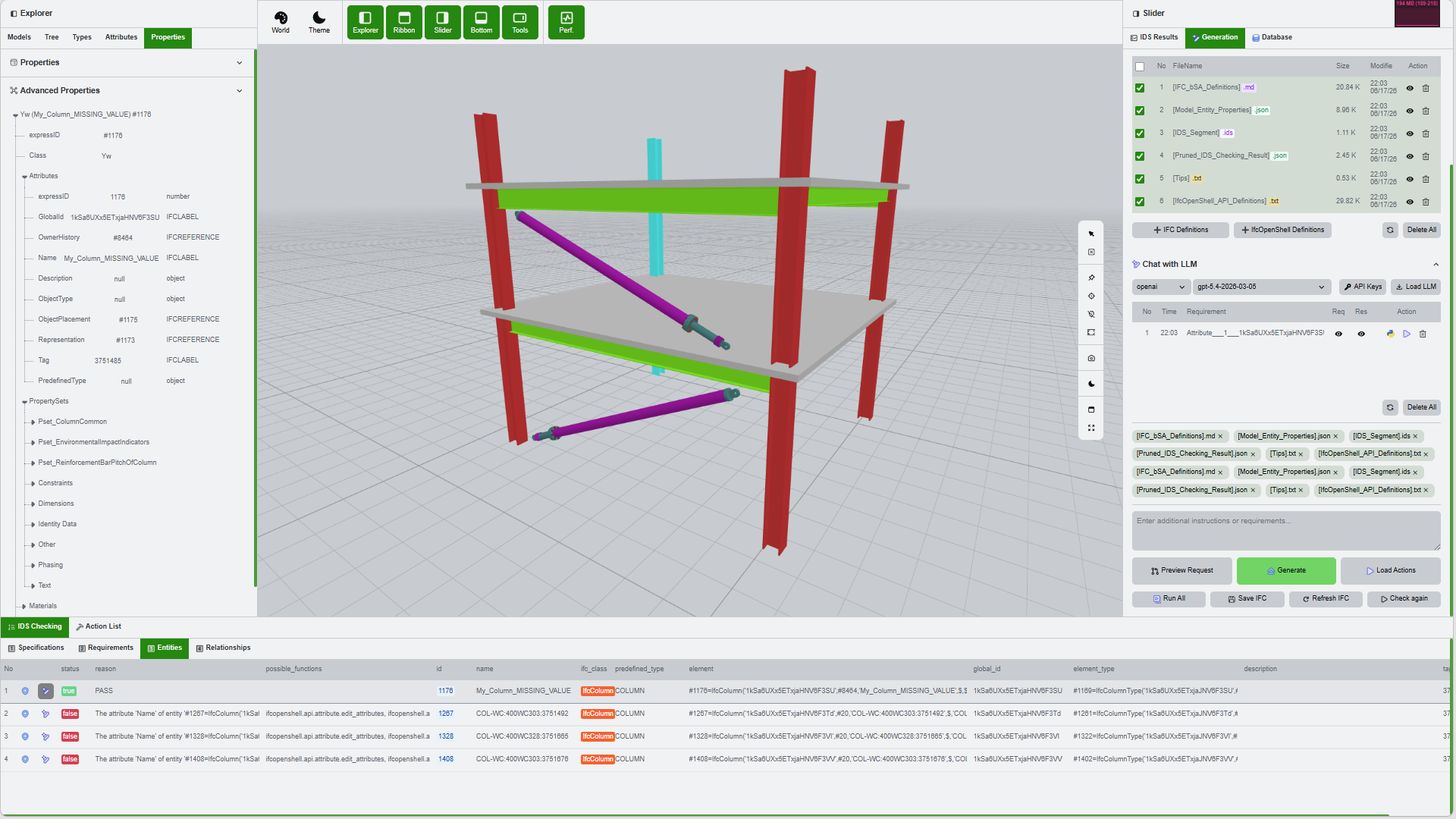
After execution, the application shows status toasts and the IDS result panel updates so you can verify whether the generated edit solved the original failure.

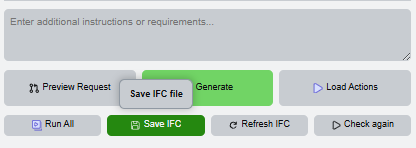
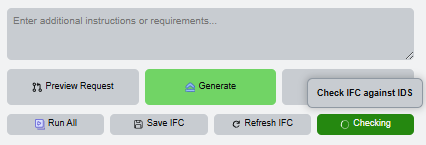
Complete the loop
The final state is a compliant or improved model with updated check results. At this point the workflow can be repeated on the same browser session for another requirement or another project file.
- Prepare the knowledge and preview the prompt.
- Send the generation request.
- Review the returned actions and command list.
- Execute the command and save the IFC state.
- Run IDS checking again.
- Compare the new result with the original failure.